쿼리 분석 및 공간 인덱스 적용기
상황
“주차의 상상은 현실이된다” 프로젝트에서 약 14,000개의 주차장 데이터를 기반으로 사용자가 목적지 주변 주차장을 쉽게 찾을 수 있도록 하는 API를 운영하고 있다.
구글 리서치 자료에 따르면, 로딩시간이 3초를 초과하면 사용자의 40%가 이탈할 가능성이 높아지며, 이는 서비스의 지속적인 사용을 저해하는 주요 원인으로 작용한다고 한다.
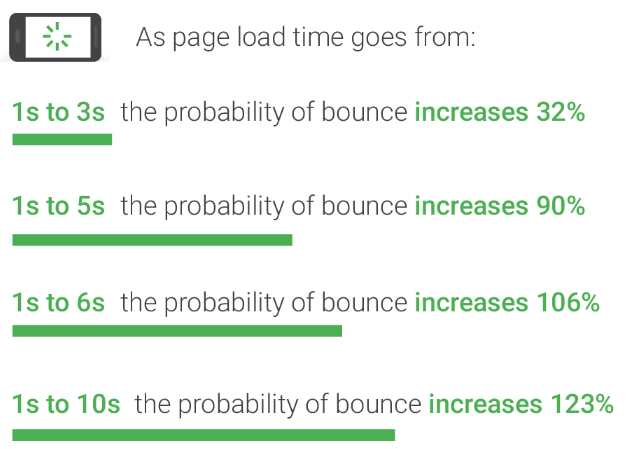
그러나, 로컬 환경에서 50명의 유저가 특정 목적지 반경 500m 내의 주차장을 10번씩 조회한다고 가정했을 때 평균 응답시간이 3853ms가 나온다.

이에 따라, 평균 응답시간 2초 이하를 목표로 잡고 개선한 과정을 작성하려고 한다.
쿼리 실행 계획 확인
실제 쿼리를 확인하기 위해 p6spy를 사용했다.
build.gradle
implementation 'com.github.gavlyukovskiy:p6spy-spring-boot-starter:1.9.0'
application.yml
spring:
datasource:
p6spy:
enable-logging: true
multiline: true
logging: slf4j
# 실제 값 확인
tracing:
include-parameter-values: true
이를 적용하고 실제 api를 호출하면 어떤 쿼리가 나가는지 확인할 수 있다.
아래는 서비스에서 목적지 주변 주차장 조회를 사용했을 때, 발생하는 쿼리이다.
select ms.session_id,ms.created_at,ms.expired_at,ms.member_id
from member_session ms
where ms.session_id='ed40a2b5-e858-44b5-9f7e-674cb993598c' and ms.expired_at>='2024-06-14T13:16:15.430+0900';
- 첫번째 발생한 쿼리는 로그인 한 사용자의 경우, 세션이 유효한지 확인하게 된다.
select f.id,f.created_at,f.member_id,f.parking_id,f.updated_at
from favorite f
where f.member_id=1;
- 이 쿼리는 로그인한 사용자의 경우, 해당 주차장에 즐겨찾기 표시를 했는지 여부를 조회하기 위한 쿼리이다.
select *
from parking p
where ST_Contains(ST_Buffer(ST_PointFromText('POINT(37.5665 126.9780)',4326), 500), p.location);
- ST의 경우 Spatial 공간의 약자로 공간 함수의 접두사로 사용된다.
- ST_Contains(G1, G2) 함수는 G1 공간 데이터에 G2 공간 데이터가 완전히 포함되는지 확인하는 함수이다.
- ST_Buffer(geometry, distance) 함수는 입력받은 공간 데이터(g)의 중심에서 distance를 반지름으로 하는 공간 데이터를 반환하는 함수이다.
- ST_PointFromText(‘POINT(37.5665 126.9780)’,4326) 함수는 WKT(Well-Known Text) 표현으로 공간 데이터를 생성하는 함수이다. (4326은 SRID의 값으로 우리가 사용하는 위도, 경도 좌표계를 나타낸다)
- 즉, 목적지 좌표를 기준으로 반지름이 500m인 원을 생성해서 해당 원안에 포함되는 주차장 좌표를 찾는 쿼리이다.
위 쿼리들 앞에 explain 키워드를 붙여 쿼리 실행계획을 확인해보면 아래와 같이 나온다.(위 순서와 동일하게 실행)

- 세션의 경우 세션 id를 이용해서 조회하기 때문에 const 타입이 나오는걸 확인할 수 있다.

- 즐겨찾기의 경우 회원 id, 주차장 id를 복합 인덱스로 가지고 있어서 ref 타입이 나오는걸 확인할 수 있다.

- 이 부분이 주차장 테이블에서 조회하고 있는 부분인데, 풀 테이블 스캔을 하고 있는 걸 알 수 있다.
조회조건인 where 절에 사용하는 주차장 테이블의 location 컬럼의 경우 공간 데이터(좌표)를 사용하고 있는데, 이를 공간 인덱스를 적용하여 개선해보자.
공간 인덱스
공간 인덱스를 적용하면 어떻게 빠르게 조회가 가능할까?
기존 인덱스의 경우 B Tree로 구성되어서 기준이 되는 키를 기준으로 정렬되어 있다.
그렇기 때문에 특정 인덱스를 조회하면 리프노드까지 비교 연산을 통해 빠르게 데이터를 찾을 수 있다.
(아래 그림에서 9를 찾는다고 가정하면 루트 노드에서 7< 9 < 16 임으로 가운데 노드로 가는걸 알 수 있다)
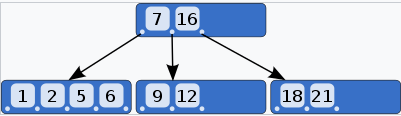
출처: 위키 백과
공간 인덱스의 경우 R tree로 구성되는데, 이는 공간 데이터를 감싸는 최소한의 사격형(Minimum Bounding Rectangle)을 만든다.
또한 이 최소 사각형을 묶는 최소 사각형을 만들며 데이터들을 묶는다. 그러면 다음과 같은 그림이 나오게 된다.
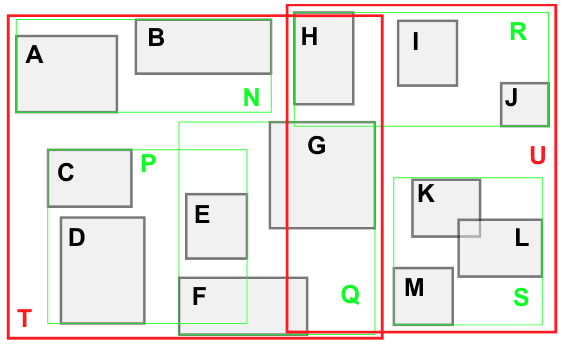
출처: IT위키
이를 트리형태로 나타내면 다음과 같다.
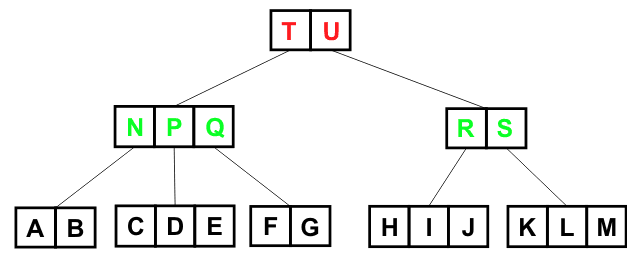
출처: IT위키
만약 여기서 특정 좌표를 조회한다고 하면 루트 노드부터 해당 사각형에 좌표가 포함되는지 확인하면된다.
T의 왼쪽 아래 좌표가 (x1, y1) 오른쪽 위 좌표가 (x2, y2)라 하고, 찾으려는 좌표를 x, y라고 한다면
(x >= x1 and x <= x2) and (y >= y1 and y <= y2) 를 비교해보면 금방 포함되는지 알 수 있다.
적용 및 결과
공간 인덱스의 경우 다음과 같이 설정해줄 수 있다.
CREATE SPATIAL INDEX parking_ix_location ON parking (location);
프로젝트에서 공간 인덱스를 생성하였음에도, 조회시에 공간 인덱스를 사용하지 못했는데
원인은 NOT NULL 조건과 컬럼의 SRID를 설정해두지 않아서였다.
주차장 좌표의 모든 데이터가 SRID 4326으로 설정되어 있어도 컬럼 자체에 SRID가 설정되어 있지 않으면 안된다.
그래서 아래와 같이 컬럼을 변경해주었다.ALTER TABLE parking MODIFY COLUMN location POINT NOT NULL SRID 4326;
인덱스를 적용하고 실행 계획을 다시 확인해보면 다음과 같이 index range scan을 하는걸 알 수 있다.

이제 같은 조건으로 다시 테스트를 해보자.

약 14,000개의 주차장 데이터에서 50명의 유저가 목적지 반경 500m의 주차장을 10번씩 조회 시
기존 3853ms에서 164ms로 약 95% 개선되었다.
리뷰 테이블에 복합 인덱스 적용
추가로 주차장 조회 이후 주차장 상세 조회가 사용되는데 쿼리를 확인해보면 다음과 같다.
select p.id,p.address,p.name,p.operation_type,p.parking_type,p.pay_types,p.tel,p.created_at,p.base_fee,p.base_time_unit,p.day_maximum_fee,p.extra_fee,p.extra_time_unit,p.holiday_free_operating_time,p.saturday_free_operating_time,p.weekday_free_operating_time,p.location,p.holiday_operating_time,p.saturday_operating_time,p.weekday_operating_time,p.capacity,p.current_parking,p.updated_at
from parking p
where p.id=153908;
- 주차장 id를 가지고 데이터를 가져온다.
select r.id,r.contents,r.created_at,r.parking_id,r.reviewer_id
from review r
where r.parking_id=153908;
- 이후, 주차장 id를 가지고 리뷰를 가지고 온다.
현재 프로젝트에서 테스트의 편의성, 결합도를 이유로 외래 키를 사용하지 않고 있다.
그래서 주차장 id를 가지고 리뷰를 조회하는 경우 쿼리 실행 계획을 살펴보면 다음과 같다.

- type을 보면 알 수 있듯이, 이 쿼리 또한 풀 테이블 스캔을 하고 있다.
리뷰 테이블에 주차장 id를 인덱스를 걸어서 해결할 수 있지만, 리뷰를 생성할 때 다음과 같은 쿼리가 나간다.
select r.id
from review r
where r.parking_id=13 and r.reviewer_id=1 limit 1;
- 비즈니스 로직상 회원은 하나의 주차장에 대해 하나의 리뷰만 작성할 수 있다.
위 쿼리에서는 주차장 id, 리뷰어 id를 사용하므로 두 쿼리에 맞춰서 각각 인덱스를 생성하기 보다, (주차장 id, 리뷰어 id) 복합 인덱스를 적용하는게 좋다고 판단했다.
CREATE UNIQUE INDEX review_ux_parking_id_reviewer_id ON review (parking_id, reviewer_id);
위와 같이 인덱스를 생성하고 다시 쿼리 실행계획을 살펴보면 다음과 같이 풀 테이블 스캔에서 ref로 변경된 걸 알 수 있다.

리뷰가 50개 존재하는 주차장을 50명의 유저가 10번씩 상세조회 했을 때를 기준으로 테스트 해보면 다음과 같다.
-
복합 인덱스 적용 전

-
복합 인덱스 적용 후

평균 응답 시간 1507ms에서 137ms으로 약 90% 개선되었다.
댓글남기기