데이터 삽입 성능 개선
상황
“주차의 상상은 현실이된다” 프로젝트에서 외부 API를 통해 주기적으로 주차장 데이터를 삽입/갱신 한다.
그러나, 이 외부 I/O 과정에서 요청을 순차적으로 처리하여 스레드의 대기 시간이 길어지고 전체 작업시간이 늘어났다.
이를, 비동기로 처리해서 작업 시간을 줄여보려 한다.
기존 프로젝트에서 데이터를 삽입하는 순서는 다음과 같다.
// 데이터 삽입 시작
c.p.e.scheduler.ParkingUpdateScheduler : Total Korea API Start
// 주차장 데이터 가져오는 API 실행
c.p.e.p.korea.KoreaParkingApiService : Korea Open API Start
c.p.e.p.korea.KoreaParkingApiService : Korea Open API Time = 154256
// 외부 데이터를 프로젝트에서 사용하는 객체로 변환 실행
c.p.e.p.korea.KoreaParkingApiService : Adapter Convert Start
c.p.e.p.korea.KoreaParkingApiService : Adapter Convert Time = 950
// 좌표 변환 API 실행
c.p.e.scheduler.ParkingUpdateScheduler : Coordinate API Start
c.p.e.scheduler.ParkingUpdateScheduler : parking size = 13444
c.p.e.scheduler.ParkingUpdateScheduler : updated parking size = 2621
c.p.e.scheduler.ParkingUpdateScheduler : Coordinate API Time = 125145
// DB 저장
c.p.e.scheduler.ParkingUpdateScheduler : DataBase Save Start
c.p.e.scheduler.ParkingUpdateScheduler : DataBase Save Time = 16124
// 종료
c.p.e.scheduler.ParkingUpdateScheduler : Total Korea API Time = 298223
- 공공 데이터 API에서 데이터 받아오기 (약 2분 30초) ← 최대 병목 지점
- 공공 데이터 응답에서 우리 객체로 변환 (약 1초)
- 좌표 없는 데이터 주소 기반으로 좌표 받아오기 (약 2분)
- 객체 데이터베이스 저장 (약 16초)
총 시간 298.223초(약 5분 소요)
비동기 처리
비동기 처리 전 간단하게 외부 API 호출하는 로직을 구현하면 다음과 같다.
static Set<Long> threads = new HashSet<>();
private static Integer testCall(Integer pageNumber, int size) {
try {
threads.add(Thread.currentThread().getId());
Thread.sleep(1000);
System.out.println("(" + Thread.currentThread().getId() + ") " + "[pageNumber] = " + pageNumber + " complete!");
} catch (InterruptedException e) {
e.printStackTrace();
}
return pageNumber;
}
- 스레드 수를 확인하기 위해 스레드 Id를 Set에 넣어주었다.
- 작업 완료를 표시하기 위해 요청 완료한 page를 출력해준다.
외부 API 호출 부분은 임의로 스레드를 1초 sleep하게 두었다. 이후, 작업을 완료하고 page number를 반환한다.
public static void main(String[] args) {
long start = System.currentTimeMillis();
System.out.println("start!");
int lastPageNumber = 615;
Set<Integer> result = new HashSet<>();
for (int pageNumber = 1; pageNumber <= lastPageNumber; pageNumber++) {
Integer response = testCall(pageNumber, SIZE);
result.add(response);
}
long end = System.currentTimeMillis();
System.out.println("threads.size() = " + threads.size());
System.out.println("time : " + (end - start));
}
외부 API를 사용하는 곳에서는 1페이지 부터 615페이지까지 데이터를 요청하고 응답을 컬랙션에 담는다.
위 로직을 실행해보면 대략 615초(외부 API 응답 처리 시간 * 요청 수)가 걸린다.
그림으로 보면 다음과 같은데, 요청을 보내고 외부 서버에서 요청을 처리하는 동안 서버에서는 대기하고 있다.

문제는 외부 API에 요청을 보내고 응답을 대기하는 시간이다.
이를 개선하기 위해서는 다음 그림과 같이 필요한 요청(1~N)을 다 보낸 후, 응답을 처리하는 것이다.
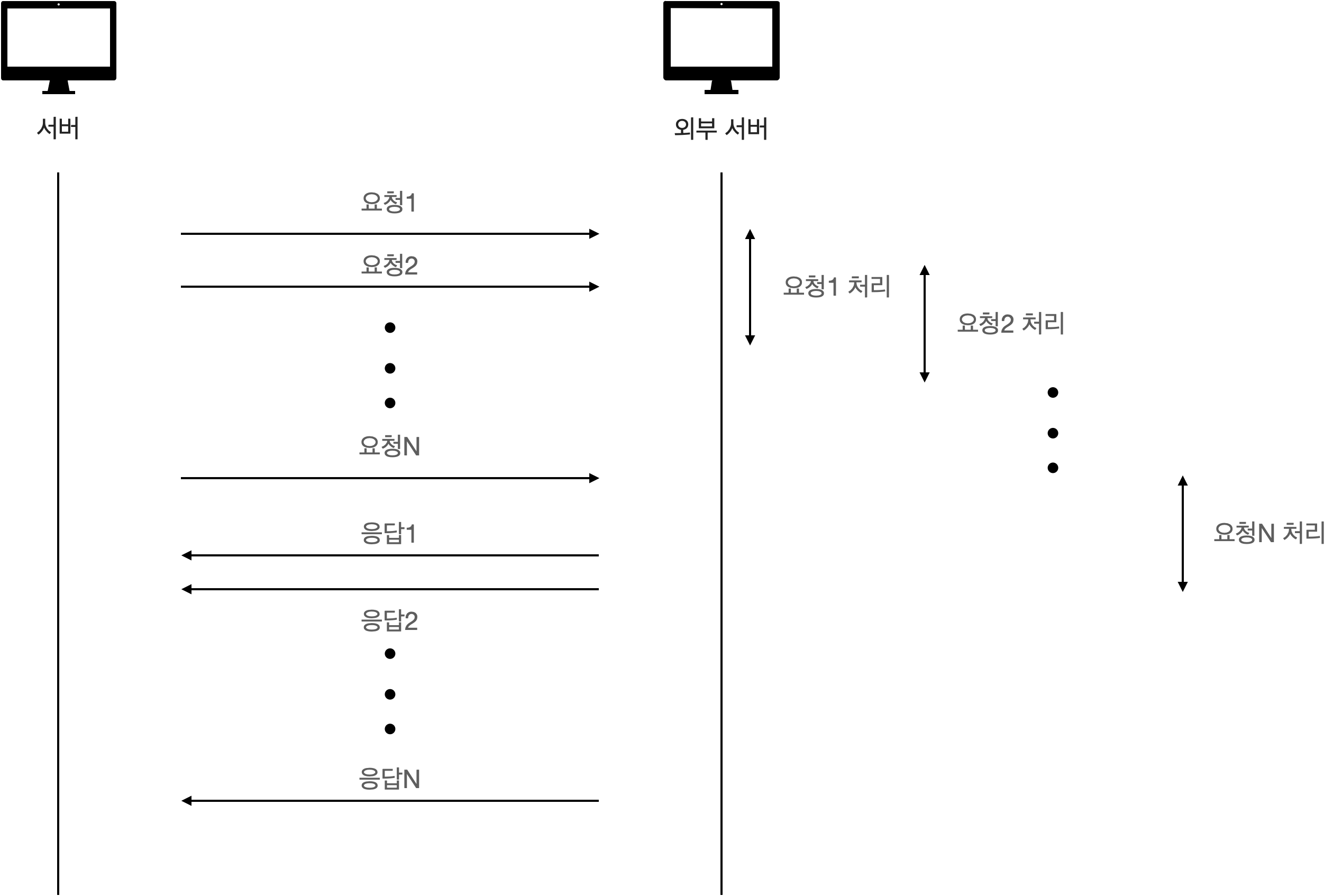
이렇게 처리하면, 요청1을 보내고 응답을 기다리지 않고 다음 요청2을 호출할 수 있다.
이전 예시 코드에서 CompletableFuture를 이용해서 코드로 적용해보면 다음과 같다.
public static void main(String[] args) {
long start = System.currentTimeMillis();
System.out.println("start!");
int pageNumber = 1;
int lastPageNumber = 615;
List<CompletableFuture<Integer>> apis = Stream.iterate(pageNumber, i -> i <= lastPageNumber, i -> i + 1)
.map(i -> CompletableFuture.supplyAsync(() -> testCall(i, SIZE)))
.toList();
Set<Integer> result = apis.stream()
.map(i -> {
Integer pageNum = i.join();
System.out.println("(" + Thread.currentThread().getId() + ") " + pageNum + " join complete");
return pageNum;
})
.collect(Collectors.toSet());
long end = System.currentTimeMillis();
System.out.println("threads.size() = " + threads.size());
System.out.println("time : " + (end - start));
}
CompletableFuture는Future를 구현한 Java에서 대표적으로 비동기 요청을 처리할 때 사용하는 객체이다.
두 map 연산을 하나의 스트림으로 처리하지 않고 두 개의 스트림으로 처리한 이유는 스트림 연산은 게으른 특성이 있으므로
위 과정을 하나의 파이프라인으로 연산을 처리했다면 모든 외부 요청을 순차적으로 이루어진다.
CompletableFuture의 join() 메서드는 비동기로 처리한 결과 값을 가져오는 데, 이 과정은 블로킹 처리된다.
이를 allOf()라는 메서드로 처리하면,Completable<Void>반환 값으로 모든 비동기 작업에 블로킹을 걸지 않아도 된다.
하지만, 해당 메서드는 원자적 특성(all Or Nothing)을 갖아 하나의 작업이 실패하면 모든 값이 null을 반환한다.
그리고 실제 값을 가져올 때는 결국 join을 사용해야 하기때문에, 위와 같이 모든 값에 join을 해주고 작업이 오래 걸릴 경우 예외 처리를 해주는게 낫다고 판단했다.
위의 코드로 실행해서 다음과 같은 결과를 얻을 수 있었다.
threads.size() = 11
time : 61211
기존 순차적으로 처리했을 때, 615초가 걸렸다면 비동기로 처리하면 61초가 걸린다. 11개의 스레드를 사용해 대략 10배 이상 빨라진걸 알 수 있다.
CompletableFuture는 ForkJoinPool을 사용하기때문에 스레드 사이즈는 기본적으로 가용 CPU 코어 수에 따라 자동으로 결정된다.
하지만 위 작업의 경우 I/O Bound 작업으로, CPU 코어 수로 작업을 할당하기보다 스레드 수를 늘려서 작업을 할당하는게 효율적이다.
적절한 스레드 수 설정
그렇다면, 스레드 수를 몇으로 설정하는 게 좋을까? 위 작업의 경우 1~615 만큼의 요청을 처리해야 하는데 스레드 수를 615로 설정한는 게 적절할까? 아래는 모던 자바 인 액션의 내용이다.
스레드 풀이 너무 크면 CPU와 메모리 자원을 서로 경쟁하느라 시간을 낭비할 수 있다.
반면 스레드 풀이 너무 작으면 CPU의 일부 코어는 활용되지 않을 수 있다.
게츠는 다음 공식으로 대략적인 CPU 활용 비율을 계산할 수 있다고 제안 한다.Nthreads = NCPU * UCPU * (1 + W/C)공식에서 NCPU, UCPU, W/C는 각각 다음을 의미한다.
- NCPU는 Runtime.getRuntime().availableProcessors()가 반환하는 코어 수
- UCPU는 0과1 사이의 값을 갖는 CPU 활용 비율
- W/C는 대기시간과 계산시간의 비율
또한, 하나의 Executor에서 사용할 스레드의 최대 개수는 100 이하로 설정하는 것이 바람직하다.
위 공식을 적용해보면 서버 상황에 적용해보자.
서버의 코어 수는 1이다. 리눅스의 경우 lscpu 명령어로 코어 수를 확인해볼 수 있다.
ubuntu@ip-172-31-41-218:~$ lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Address sizes: 46 bits physical, 48 bits virtual Byte Order: Little Endian CPU(s): 1 On-line CPU(s) list: 0 Vendor ID: GenuineIntel Model name: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz CPU family: 6 Model: 79 Thread(s) per core: 1 Core(s) per socket: 1 Socket(s): 1CPU당 코어(Core(s) per socket), 코어당 스레드(Thread(s) per core)를 보면 하나의 스레드를 사용할 수 있는 걸 알 수 있다.
W/C의 경우 주차장 데이터를 가져오는 시간이 154256, 데이터를 처리하는 시간이 950임으로 나눠보면 대략 162가 나온다.
CPU 활용 비율을 100% 즉, 1로 계산 해보면 스레드 수 = 1(컴퓨터 코어 수) * 1(cpu 활용 비율) * 162 = 162 가 나온다.
그러나, 컨텍스트 스위칭 비용을 생각해 100개 이하로 설정하는 게 바람직하므로 100개로 스레드를 설정하면 된다.
기존 코드를 다음과 같이 수정하자.
ExecutorService executorService = Executors.newFixedThreadPool(100, (Runnable r) -> {
Thread thread = new Thread(r);
thread.setDaemon(true);
return thread;
}
);
List<CompletableFuture<Integer>> apis = Stream.iterate(pageNumber, i -> i <= lastPageNumber, i -> i + 1)
.map(i -> CompletableFuture.supplyAsync(() -> testCall(i, SIZE), executorService))
.toList();
데몬 스레드로 설정한 이유는 어떤 이벤트를 한없이 기다리면서 종료되지 않는 일반 스레드가 있으면 문제가 될 수 있다.
반면 데몬 스레드는 자바 프로그램이 종료될 때 강제 로 실행이 종료될 수 있다.
수정 후, 실행해보면 다음과 같은 결과가 나온다.
threads.size() = 100
time : 7030
1초가 걸리는 외부 API를 615개 요청을 보냈을 때, 대략 7초가 걸리는 걸 알 수 있다.
객체 데이터베이스 저장 개선
현재 데이터를 저장할 때 saveAll()을 사용하고 있다. 이는 연결은 한번만 맺지만 데이터 하나를 저장할 때마다 insert 쿼리를 날린다.
전국 주차장 API를 모두 읽으면 데이터가 13,444개가 들어오는데, 이를 하나하나 쿼리로 날리는건 매우 비효율적이다.
이를, JdbcTemplate을 이용해서 bulk로 처리하여 하나의 쿼리로 개선하자.
적용하는 방법은 다음과 같다.
- insert 쿼리 작성 (필드에 들어가는 값은 ‘?’로 표기)
- PreparedStatement 작성, (엔티티의 값들이 어떻게 테이블의 필드에 매핑될지)
- JdbcTemplate의 batchUpdate 실행
위 과정만 코드로 적용하면 된다.
아래는 프로젝트에서 사용한 주차장 테이블에 적용한 코드이다.
@RequiredArgsConstructor
@Repository
public class ParkingBulkRepository {
private final ParameterizedPreparedStatementSetter<Parking> PARKING_PARAMETERIZED_PREPARED_STATEMENT_SETTER = (PreparedStatement ps, Parking parking) -> {
ps.setInt(1, parking.getFeePolicy().getBaseFee().getFee());
ps.setInt(2, parking.getFeePolicy().getBaseTimeUnit().getTimeUnit());
ps.setInt(3, parking.getFeePolicy().getExtraFee().getFee());
ps.setInt(4, parking.getFeePolicy().getExtraTimeUnit().getTimeUnit());
ps.setInt(5, parking.getFeePolicy().getDayMaximumFee().getFee());
ps.setInt(6, parking.getSpace().getCapacity());
ps.setInt(7, parking.getSpace().getCurrentParking());
ps.setObject(8, parking.getOperatingTime().getHolidayBeginTime());
ps.setObject(9, parking.getOperatingTime().getHolidayEndTime());
ps.setObject(10, parking.getFreeOperatingTime().getHolidayBeginTime());
ps.setObject(11, parking.getFreeOperatingTime().getHolidayEndTime());
ps.setObject(12, parking.getOperatingTime().getSaturdayBeginTime());
ps.setObject(13, parking.getOperatingTime().getSaturdayEndTime());
ps.setObject(14, parking.getFreeOperatingTime().getSaturdayBeginTime());
ps.setObject(15, parking.getFreeOperatingTime().getSaturdayEndTime());
ps.setObject(16, parking.getOperatingTime().getWeekdayBeginTime());
ps.setObject(17, parking.getOperatingTime().getWeekdayEndTime());
ps.setObject(18, parking.getFreeOperatingTime().getWeekdayBeginTime());
ps.setObject(19, parking.getFreeOperatingTime().getWeekdayEndTime());
ps.setObject(20, parking.getCreatedAt());
ps.setObject(21, parking.getUpdatedAt());
ps.setString(22, parking.getBaseInformation().getAddress());
ps.setString(23, parking.getBaseInformation().getName());
ps.setString(24, parking.getBaseInformation().getTel());
ps.setString(25, parking.getBaseInformation().getOperationType().name());
ps.setString(26, parking.getBaseInformation().getParkingType().name());
ps.setString(27, parking.getBaseInformation().getPayTypesName());
ps.setString(28, toWKT(parking.getLocation()));
};
private String toWKT(Location location) {
return "POINT(" + location.getLatitude() + " " + location.getLongitude() + ")";
}
private final JdbcTemplate jdbcTemplate;
@Transactional
public void saveAllWithBulk(List<Parking> parkingLots) {
String sql = "INSERT INTO parking "
+ "(base_fee, base_time_unit, extra_fee, extra_time_unit, day_maximum_fee, "
+ "capacity, current_parking, "
+ "holiday_begin_time, holiday_end_time, holiday_free_begin_time, holiday_free_end_time, "
+ "saturday_begin_time, saturday_end_time, saturday_free_begin_time, saturday_free_end_time, "
+ "weekday_begin_time, weekday_end_time, weekday_free_begin_time, weekday_free_end_time, "
+ "created_at, updated_at, "
+ "address, name, tel, operation_type, parking_type, pay_types, location) "
+ "VALUES "
+ "(?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ST_GeomFromText(?))";
jdbcTemplate.batchUpdate(
sql,
parkingLots,
parkingLots.size(),
PARKING_PARAMETERIZED_PREPARED_STATEMENT_SETTER
);
}
}
- 좌표를 Geometry 타입(Mysql 8.3)으로 사용하고 있는데, 쿼리로 작성할 때는
ST_GeomFromText(?)이 형식으로 작성해주고
값은POINT(x y)이 형식의 String을 넣어주면 된다.
테이블의 속성이 많아 복잡해서 그렇지 간단하다.
추가로 Mysql에서 SQL문을 개별로 실행하기 때문에 rewriteBatchedStatements=true 옵션을 url에 적용해줘야 한다.
spring:
datasource:
url: ${DB_URL:jdbc:mysql://localhost:3306/database_name?rewriteBatchedStatements=true}
이렇게만 적용했을 때, 데이터 13,444개 기준 OOM이 발생했다.
batchUpdate 메서드를 살펴보면 1106 번라인에 다음과 같은 코드가 있다.
for (T obj : batchArgs) {
pss.setValues(ps, obj);
n++;
if (batchSupported) {
ps.addBatch();
if (n % batchSize == 0 || n == batchArgs.size()) {
if (logger.isTraceEnabled()) {
int batchIdx = (n % batchSize == 0) ? n / batchSize : (n / batchSize) + 1;
int items = n - ((n % batchSize == 0) ? n / batchSize - 1 : (n / batchSize)) * batchSize;
logger.trace("Sending SQL batch update #" + batchIdx + " with " + items + " items");
}
rowsAffected.add(ps.executeBatch());
}
}
else {
int i = ps.executeUpdate();
rowsAffected.add(new int[] {i});
}
}
문제가 될만한 부분은 ps.addBatch()로 계속해서 SQL 명령이 메모리에 저장된다.
작성한 쿼리의 문자열이 대략 500 character 임으로 1000 bytes
각 파라미터가 평균 10 character라고 가정하고 총 28개의 파라미터임으로 560 bytes
총 데이터 수가 대략 10,000개 임으로 대략 1560 * 10,000 = 15.6 MB임을 알 수 있다.
이를 개선하기 위해 처리되는 데이터 수를 Batch로 나눌필요가 있다고 판단했다.
@RequiredArgsConstructor
@Repository
public class ParkingBatchRepositoryImpl implements ParkingBatchRepository {
private final int BATCH_SIZE = 2000;
private final ParkingBulkRepository parkingBulkRepository;
@Override
public void saveWithBatch(List<Parking> parkingLots) {
for (int i = 0; i < parkingLots.size(); i += BATCH_SIZE) {
int end = Math.min(i + BATCH_SIZE, parkingLots.size());
List<Parking> subParkingLots = parkingLots.subList(i, end);
parkingBulkRepository.saveAllWithBulk(subParkingLots);
}
}
}
기존에 한번에 처리하는 쿼리를 Batch Size 2000개로 나누고 저장하는 방식이다.
이렇게 적용하면 메모리 사용을 줄이고, 트랜잭션 범위를 Batch Size만큼 줄일 수 있다.
결과
위 과정을 적용하고 시간을 다시 측정해보면 다음과 같다.
// 데이터 삽입 시작
c.p.e.scheduler.ParkingUpdateScheduler : Total Korea API Start
// 주차장 데이터 가져오는 API 실행
c.p.e.p.korea.KoreaParkingApiService : Korea Open API Start
c.p.e.p.korea.KoreaParkingApiService : Korea Open API Time = 23031
// 외부 데이터를 프로젝트에서 사용하는 객체로 변환 실행
c.p.e.p.korea.KoreaParkingApiService : Adapter Convert Start
c.p.e.p.korea.KoreaParkingApiService : Adapter Convert Time = 1149
// 좌표 변환 API 실행
c.p.e.scheduler.ParkingUpdateScheduler : Coordinate API Start
c.p.e.scheduler.ParkingUpdateScheduler : parking size = 13444
c.p.e.scheduler.ParkingUpdateScheduler : updated parking
c.p.e.scheduler.ParkingUpdateScheduler : Coordinate API Time = 143533
// DB 저장
c.p.e.scheduler.ParkingUpdateScheduler : DataBase Save Start
c.p.e.scheduler.ParkingUpdateScheduler : DataBase Save Time = 4285
// 종료
c.p.e.scheduler.ParkingUpdateScheduler : Total Korea API Time = 173930
- 공공 데이터 API에서 데이터 받아오기 (약 2분 30초 -> 23초) ← 최대 병목 지점
- 공공 데이터 응답에서 우리 객체로 변환 (약 1초 -> 약 1초)
- 좌표 없는 데이터 주소 기반으로 좌표 받아오기 (약 2분 -> 약 2분)
- 이 부분도 비동기로 처리해서 개선하고 싶었으나, 429 Too many Requests로 응답이 왔다.
초당 횟수 제한이 있어, 30ms 시간차를 두고 보냈으나 동기로 처리하는게 2배 이상 빨랐다. - 이 작업은 데이터가 처음 들어올 때, 처리되는 작업이라 기존대로 유지하기로 했다.
- 이 부분도 비동기로 처리해서 개선하고 싶었으나, 429 Too many Requests로 응답이 왔다.
- 객체 데이터베이스 저장 (약 16초 -> 4초)
총 시간 298.223초에서 173.93초로 대략 41% 속도가 개선 되었다.
참고
모던 자바 인 액션
댓글남기기